Universalabgleich
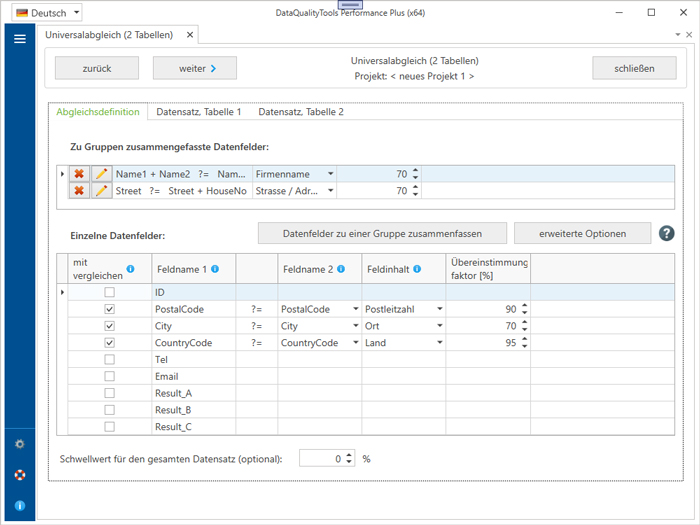
Bei dieser Funktionen können die für den Dublettenabgleich zu verwendenden Spalten und die darauf anzuwendenden Kriterien frei festgelegt werden. Für jede Spalte kann dabei festgelegt werden ob diese mit verglichen werden soll oder nicht.
Soll ein Datenfeld mit vergleichen werden, dann sind dazu die folgenden Angaben zu machen:
- Feldinhalt: Art des Inhalts des Datenfelds. Die hier getroffene Auswahl sollte den Inhalt des Datenfelds möglichst genau beschreiben, damit das Programm die Daten beim Vergleich passend behandeln kann. Bei einem Datenfeld, das eine Postleitzahl enthält sollte also auch 'Postleitzahl' als Feldinhalt gewählt werden.
- Übereinstimmungsfaktor: Schwellwert für den Übereinstimmungsfaktor in Prozent, der für das betreffende Spaltenpaar oder die Gruppe mindestens erreicht werden muss.
Enthalten mehrere Datenfelder den gleichen Feldinhalt, dann können diese zu einer Gruppe zusammengefasst werden. Dadurch wird dann entweder deren Inhalt für den Vergleich zusammengefasst oder es wird jedes Datenfeld der einen Gruppe einzeln mit jedem Datenfeld aus der anderen Gruppe verglichen.
Für den für den gesamten Datensatz errechneten Übereinstimmungsfaktor kann optional noch ein eigener Schwellwert festgelegt werden.
Darüber hinaus können bei Bedarf noch die folgenden Optionen verwendet werden:
- Mehrere Abgleichsdefinitionen: Damit können mehrere unterschiedliche Vergleichskriterien festgelegt werden, die dann nacheinander abgearbeitet werden. Das könnten beispielsweise, ähnlich wie beim All-in-One-Abgleich, die Telefonnummer, die Emailadresse und die postalische Adresse sein.
- Gewichtung: Durch das reduzieren des Gewichts von weniger wichtigen Datenfeldern kann erreicht werden, dass diese den für den gesamten Datensatz errechneten Übereinstimmungsfaktor nur wenig beeinflussen.
- Datensatz überspringen wenn das Datenfeld leer ist: Damit können unvollständige Datensätze vom Vergleich ausgeschlossen werden.
- Bedingung, die nicht zutreffen darf: In diesem Fall muss der Schwellwert für den Übereinstimmungsfaktor nicht über- sondern unterschritten werden, um zu einem Treffer zu führen. Damit können beispielsweise Datensätze ermittelt werden bei denen zwar der Vorname übereinstimmt, nicht aber die persönliche Anrede. Oder es könnte damit dafür gesorgt werden, dass beim Vergleich zweier Tabellen zwei Datensätze nicht mit verglichen werden wenn deren ID identisch ist.
Nachdem sich das Abgleichkriterium bei dieser Funktion frei zusammenstellen lässt, sind hier die unterschiedlichsten Anwendungen denkbar: So könnte über das Geburtsdatum, über die Bankverbindung oder über die Kreditkartennummer abgeglichen werden. Aber es könnten auch Tabellen abgeglichen werden die etwas anderes als Adressdaten enthalten, beispielsweise über die Artikelbezeichnung, den Buchtitel oder eine Anmerkung.